
To fix Kubernetes on a Linux server, start with a quick health triage: confirm OS prerequisites (swap off, cgroups, kernel modules), verify kubelet and the container runtime, check kubectl and cluster components, repair CNI networking and DNS, validate certificates and etcd, then apply targeted fixes or safely reset and rejoin nodes if needed.
If you’re wondering how to fix Kubernetes on a Linux server, this guide walks you through a practical, step by step troubleshooting workflow I use in real environments.
We’ll diagnose kubelet, container runtimes, networking (CNI), DNS, certificates, etcd, and performance issues, using simple commands, minimal downtime tips, and safe rollback options.
Quick Diagnosis Checklist
Before deep diving, run through this rapid checklist to pinpoint the layer causing the failure. Fixes become much faster when you narrow scope early.
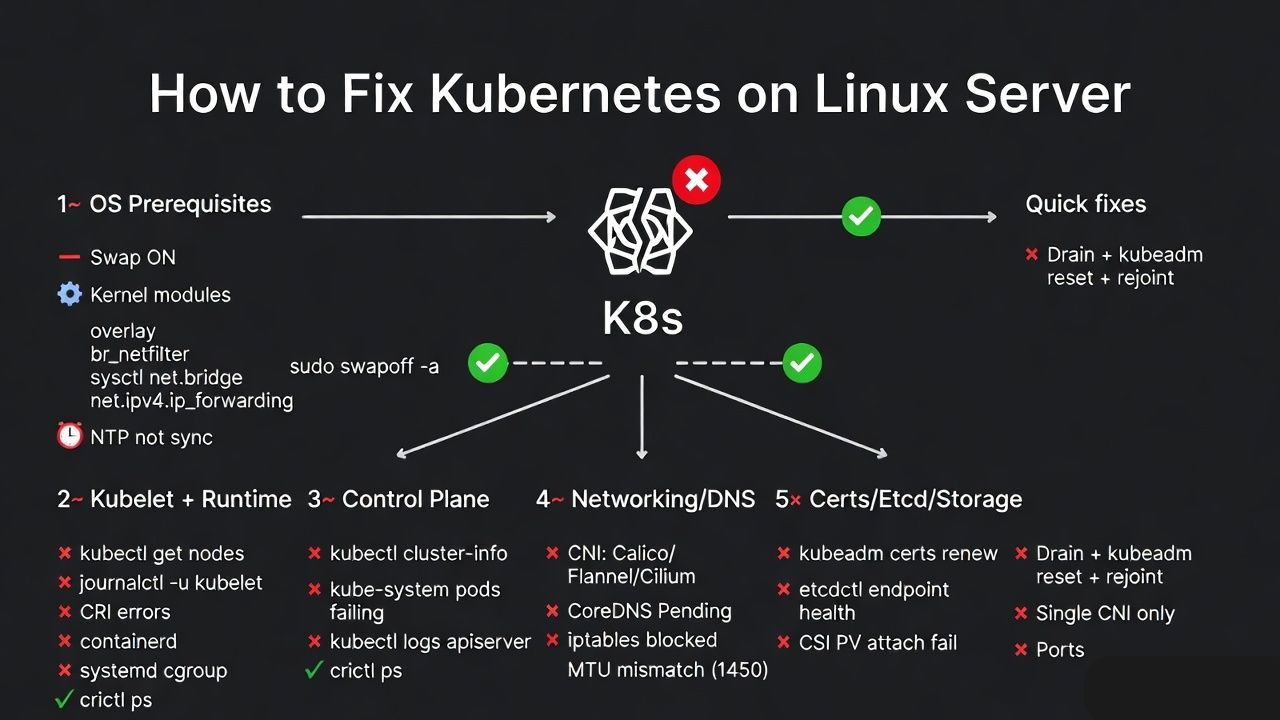
1) Validate Node and OS Prerequisites
- Disable swap (or configure kubelet to tolerate it).
- Load required kernel modules and sysctls for bridging and forwarding.
- Confirm time sync and unique hostnames.
- Check firewall rules and open Kubernetes/CNI ports.
# Swap should be off
sudo swapoff -a
sudo sed -ri 's/^([^#].*\sswap\s)/# \1/' /etc/fstab
# Kernel modules
sudo modprobe overlay
sudo modprobe br_netfilter
# Sysctls
cat <<'EOF' | sudo tee /etc/sysctl.d/99-kubernetes.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
# Time sync
timedatectl
sudo systemctl status chronyd || systemctl status systemd-timesyncd
# Hostname must be unique and resolvable
hostnamectl2) Check kubelet and Container Runtime
- Ensure kubelet is running and able to talk to the container runtime (containerd/CRI-O).
- Look for cgroup driver mismatches and CRI errors.
# Kubelet
sudo systemctl status kubelet --no-pager
sudo journalctl -u kubelet -b --no-pager
# Containerd (example runtime)
sudo systemctl status containerd --no-pager
containerd --version
sudo crictl info
sudo crictl ps -a3) Verify kubectl Context and Control Plane Health
kubectl config get-contexts
kubectl cluster-info
kubectl get nodes -o wide
kubectl get pods -A --field-selector=status.phase!=Running
kubectl get componentstatuses # deprecated info, prefer:
kubectl -n kube-system get pods
kubectl -n kube-system logs -l component=kube-apiserver --tail=2004) Confirm Networking and DNS
- Ensure a single CNI is installed and healthy (Calico, Flannel, Cilium, etc.).
- Check CoreDNS logs and service discovery from inside a Pod.
- Inspect iptables/ipvs and MTU settings.
# CNI presence
ls /etc/cni/net.d
ls /opt/cni/bin
# CoreDNS
kubectl -n kube-system get pods -l k8s-app=kube-dns
kubectl -n kube-system logs -l k8s-app=kube-dns --tail=200
# kube-proxy and iptables/ipvs
kubectl -n kube-system get pods -l k8s-app=kube-proxy
sudo iptables -L -n -v
ip link | grep -E 'mtu|cali|flannel|cilium'5) Storage and Events
- Describe failing Pods for Events and volume errors.
- Check CSI drivers and node disk pressure.
kubectl describe pod <name> -n <ns>
kubectl get csidrivers
kubectl describe node <node> | egrep -i 'taints|pressure|memory|disk'Common Kubernetes Issues on Linux and How to Fix Them
Kubelet Won’t Start (Swap, Cgroups, Runtime)
- Disable swap. Kubernetes expects swap off unless kubelet is run with
--fail-swap-on=false(not recommended). - Align cgroup drivers. On modern distros, Kubernetes + containerd with systemd cgroups is recommended.
- Ensure container runtime socket is reachable by kubelet.
# Containerd systemd cgroup example (config.toml)
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml >/dev/null
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
sudo systemctl restart containerd
sudo systemctl restart kubeletIf logs show “Failed to run kubelet” or “failed to run Kubelet: validate service connection” confirm --container-runtime-endpoint matches your runtime socket (e.g., unix:///run/containerd/containerd.sock ).
Pods Stuck in Container Creating (CNI Problems)
- Make sure only one CNI plugin is configured.
- Reapply the correct CNI manifest after wiping stale configs.
- Open overlay/VXLAN ports and fix MTU on cloud networks.
# Remove stale CNI configs carefully (multi-tenant warning!)
sudo rm -f /etc/cni/net.d/*
# Reapply your chosen CNI (example: Calico docs provide latest URL)
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.0/manifests/calico.yaml
# Example MTU for encapsulation networks (adjust to your infra, often 1450 or 1440)
# Calico: set vethMTU in configmap or operator CR
# Flannel: net-conf.json "MTU": 1450On RHEL/CentOS, ensure firewalld or iptables isn’t blocking pod traffic. On Ubuntu with UFW, allow inter-node traffic or disable UFW for Kubernetes nodes when testing.
DNS Failures (CoreDNS CrashLoop/Timeouts)
- Check CoreDNS logs for loop or forwarding errors.
- Validate the
kube-dnsservice and clusterDNS IP in kubelet config. - Test DNS from a debug pod.
# Quick DNS test
kubectl run -it dnsutils --image=ghcr.io/k8s-at-home/dnsutils:latest --restart=Never --rm --overrides='{"spec":{"dnsPolicy":"ClusterFirst"}}' -- nslookup kubernetes.default
# Check kubelet resolv.conf flags
cat /var/lib/kubelet/config.yaml | egrep 'clusterDNS|clusterDomain'
kubectl -n kube-system get svc kube-dnsCertificates Expired (APIServer, Kubelets)
If your control plane is built with kubeadm, use the built in cert utilities. Renewing certs is fast and low risk when done early.
sudo kubeadm certs check-expiration
sudo kubeadm certs renew all
sudo systemctl restart kubeletFor worker nodes failing to join due to certs or tokens, create a fresh token and rejoin using the printed command.
kubeadm token create --print-join-commandetcd Health and Data Store Issues
- Check etcd endpoint health with proper certs.
- Watch for disk latency and space exhaustion; etcd is sensitive to I/O.
- Ensure time sync across control plane nodes.
export ETCDCTL_API=3
etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key endpoint healthIf etcd is unhealthy, avoid “quick fixes” that risk data loss. Snapshot first, then recover. Consider restoring from a verified etcd snapshot if corruption is suspected.
kubeadm Join/Upgrade Fails
- Match Kubernetes versions: upgrade kubeadm first, then control plane, then kubelet/kubectl.
- Regenerate a join command and ensure ports to the API server are reachable.
# Plan an upgrade
sudo kubeadm upgrade plan
# Upgrade components (Ubuntu example)
sudo apt-get update
sudo apt-get install -y kubeadm=<version>-00
sudo kubeadm upgrade apply <version>
# Then upgrade kubelet/kubectl and restart kubelet
sudo apt-get install -y kubelet=<version>-00 kubectl=<version>-00
sudo systemctl daemon-reload && sudo systemctl restart kubeletPersistent Volume Mount/Attach Errors
- Check CSI driver logs and node dmesg for attach/mount errors.
- Validate cloud credentials/permissions for dynamic provisioning.
- Ensure matching filesystem and access modes.
kubectl -n kube-system logs -l app=csi-controller --tail=200
kubectl describe pvc <name> -n <ns>
dmesg | tail -n 100Performance and Stability Tuning
- Use containerd with systemd cgroups for modern Linux.
- Prefer kube proxy ipvs on larger clusters; otherwise iptables is fine.
- Enable log rotation for containers and keep OS/disk clean.
- Pin tested kernel versions and avoid unexpected kernel jumps.
# kube-proxy mode (check ConfigMap)
kubectl -n kube-system get cm kube-proxy -o yaml | grep mode
# Example container log rotation (containerd via CRI)
# Configure containerd & CRI log options or use logrotate for /var/log/containersWhen to Reset or Rebuild Safely
If a node is deeply misconfigured (broken CNI, runtime conflicts, or stale state), a clean reset can be fastest. Drain the node, reset kubeadm, and rejoin with a fresh token. This preserves cluster workloads by rescheduling pods elsewhere.
# Move workloads off the node
kubectl drain <node> --ignore-daemonsets --delete-emptydir-data --force
# Reset node state
sudo kubeadm reset -f
sudo systemctl restart containerd || sudo systemctl restart crio
sudo rm -rf ~/.kube
# Rejoin node (from control plane)
kubeadm token create --print-join-command
# Run the printed join command on the node
# Mark schedulable again
kubectl uncordon <node>Preventing Future Incidents
- Configuration management: codify kubelet, containerd, sysctls, and CNI with Ansible/Terraform.
- Monitoring and alerts: watch kubelet, etcd, CoreDNS, API latencies, and node pressures.
- Backups: automate etcd snapshots and offsite backups.
- Security baseline: restrict SSH, patch OS, rotate tokens/certs, and use RBAC least privilege.
- Change control: test CNI/runtime/kube-proxy changes in staging before production.
When You Need Hands On Help
Running Kubernetes on bare metal or cloud Linux servers can be unforgiving. If you host your control plane or workers with YouStable, our engineers can audit your cluster, tune kernel and cgroups, right size networking (MTU, ipvs/iptables), implement etcd backups, and establish reliable monitoring, so fixes become routine and outages rare.
Actionable Fix Recipes (Copy/Paste)
Open Required Ports (Example)
# Control-plane node (firewalld example)
sudo firewall-cmd --permanent --add-port=6443/tcp # kube-apiserver
sudo firewall-cmd --permanent --add-port=2379-2380/tcp # etcd
sudo firewall-cmd --permanent --add-port=10250/tcp # kubelet
sudo firewall-cmd --permanent --add-port=10257/tcp # kube-controller-manager
sudo firewall-cmd --permanent --add-port=10259/tcp # kube-scheduler
sudo firewall-cmd --reload
# Worker node
sudo firewall-cmd --permanent --add-port=10250/tcp
sudo firewall-cmd --permanent --add-port=30000-32767/tcp # NodePort range
sudo firewall-cmd --reloadFix NetworkManager Interference
# Tell NetworkManager to ignore CNI bridges (e.g., cni0, flannel.1, cali*)
cat <<'EOF' | sudo tee /etc/NetworkManager/conf.d/90-k8s-cni.conf
[keyfile]
unmanaged-devices=interface-name:cni*,interface-name:flannel*,interface-name:cali*,interface-name:tunl*
EOF
sudo systemctl reload NetworkManagerSELinux Considerations (RHEL/CentOS)
# For quick testing only (prefer proper policies in production)
sudo setenforce 0
# To make permissive across reboots (evaluate security impact)
sudo sed -i 's/^SELINUX=enforcing/SELINUX=permissive/' /etc/selinux/configFAQs
Why is kubelet not starting on my Linux server?
Most often because swap is enabled, the container runtime socket is unreachable, or cgroup drivers don’t match. Disable swap, set containerd’s SystemdCgroup=true, restart containerd and kubelet, and review journalctl -u kubelet for CRI errors.
How do I fix CrashLoopBackOff pods?
Describe the pod to see the last exit codes and reasons. Then check container logs. Common fixes include correcting image pull secrets, fixing environment variables, increasing resources, or resolving ConfigMap/Secret mount paths. If it’s a node issue, look for disk pressure or runtime errors.
CoreDNS is Pending or timing out, what should I check?
Ensure a CNI is installed and functioning, verify the kube-dns service, and inspect CoreDNS logs for loop/forwarding errors. Test DNS from a debug pod. If you’re on cloud networks, confirm MTU and that firewall rules allow pod to pod traffic.
Is it safe to run kubeadm reset to fix a broken node?
Yes, if you drain the node first. kubeadm reset clears local state so you can rejoin cleanly. Always drain with kubectl drain, reset, then use a fresh join command. For control plane nodes, plan downtime and have etcd backups.
Which ports must be open for Kubernetes to work?
Commonly: 6443/tcp (API), 2379–2380/tcp (etcd control plane), 10250/tcp (kubelet), 10257/tcp (controller-manager), 10259/tcp (scheduler), and 30000–32767/tcp for NodePort services. Your CNI may require additional ports (e.g., 8472/udp for Flannel VXLAN, 179/tcp for Calico BGP).


