
Slow responses, random crashes, and models failing when they matter most often come from limited local system resources. Modern LLMs require stable RAM, strong processing power, and consistent uptime, which most personal setups cannot handle efficiently, leading to unstable performance and frequent execution issues.
A more reliable solution is to run LLM locally on VPS, where dedicated resources and better uptime create a stable environment. This setup improves performance, reduces failures, and supports real workloads. With the right configuration, your LLM runs smoothly, consistently, and without unnecessary interruptions.
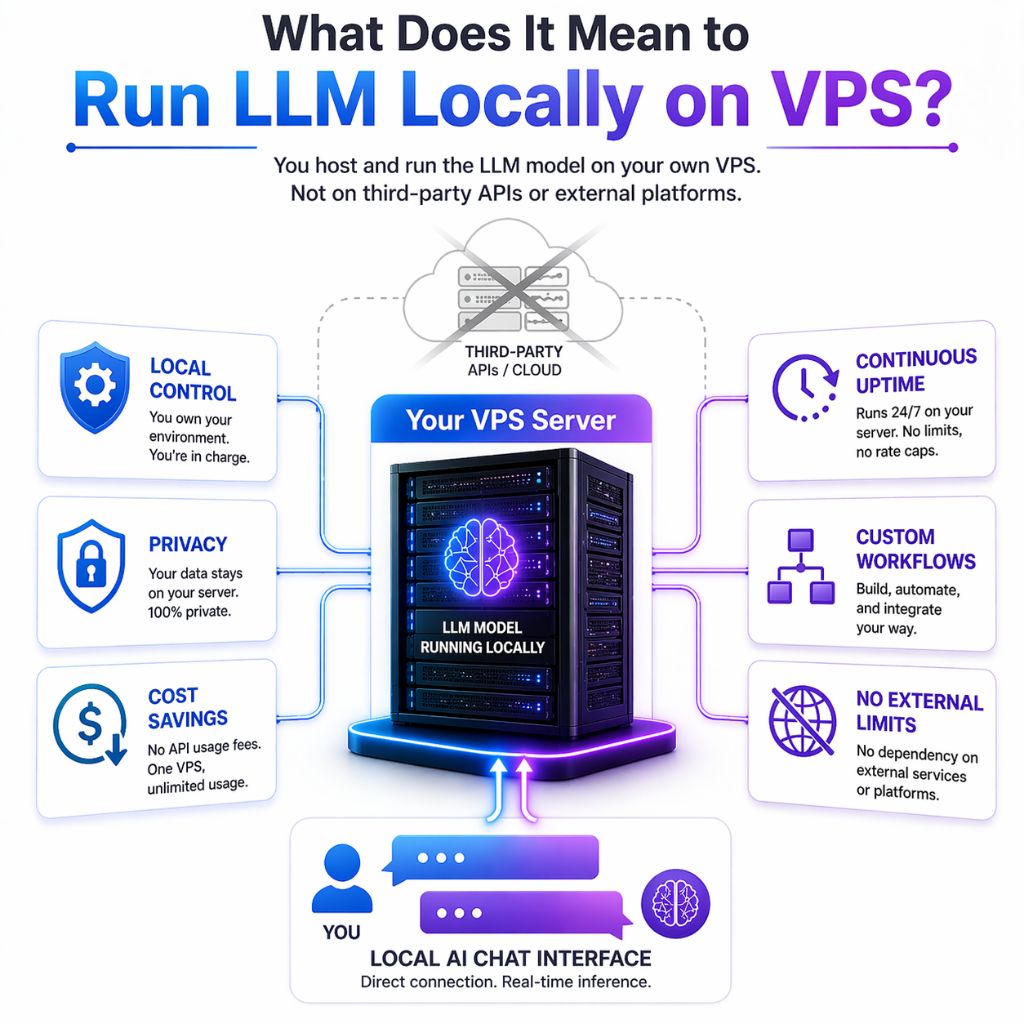
What Does It Mean to Run LLM Locally on VPS?
Running an LLM locally on a VPS means you host and execute the model on your own server environment instead of relying on third party APIs or external platforms. Even though the server is remote, it works like your personal system, where you control how the model is installed, configured, and used without external limitations.
This setup gives you full control over performance, privacy, and cost.
You can manage your data securely, avoid ongoing API charges, and run the model continuously for automation or real world applications.
It is especially useful when you want stable output, customizable workflows, and a reliable environment that is not dependent on external services or usage limits.
Why Use a VPS Instead of Local System?
A local system can handle basic testing, but it quickly reaches its limits when you start running LLMs regularly. Most personal machines struggle with limited RAM, average CPUs, and no dedicated GPU, which leads to slow responses, crashes, or failed executions. On top of that, everything depends on your device being active, so any shutdown or interruption directly stops your workflows.
A VPS provides a much more reliable and scalable environment for running LLMs. It runs continuously, offers dedicated resources, and allows you to upgrade CPU, RAM, or storage as your workload grows. This makes your setup more stable, faster, and suitable for real world use. Choosing a consistent VPS platform such as YouStable further improves performance by reducing downtime and handling heavy workloads without interruptions.
Minimum VPS Requirements for Running LLM
If you are just starting with LLMs or working with smaller models (around 1B–7B parameters), you don’t need a high end server. A basic VPS setup is enough to run these models for testing, learning, and light automation tasks. However, even small models still require a stable environment, so choosing the right minimum configuration is important to avoid slowdowns or unexpected crashes.
Basic Requirements Explained
- CPU: 4–8 Cores
A modern multi core CPU helps manage system processes and model execution. While LLMs rely more on GPU for speed, a decent CPU ensures the system runs smoothly without bottlenecks.
- AM: 8–16 GB
RAM is critical because the model needs to load into memory during execution. With less than 8 GB, you may face startup failures or crashes. 16 GB provides better stability for smoother performance.
- Storage: 50 GB SSD (Recommended)
Fast storage like SSD ensures quicker model loading and better data access. HDD can slow down the process significantly, especially when working with larger files.
- GPU: Optional (4–8 GB VRAM if available)
A GPU is not required for small models, but it can significantly improve response speed. Without GPU, the model will run on CPU, which is slower but still usable for basic tasks.
What You Can Expect from This Setup
This configuration works well for:
- Learning how LLMs work
- Running small models
- Testing prompts and workflows
- Basic automation tasks
However, performance will be limited. You may notice slower responses, especially without GPU acceleration. This setup is not ideal for handling multiple requests or running larger models.
Recommended VPS Setup for Smooth Performance
For medium sized LLMs (around 7B–13B parameters), a balanced VPS configuration is important to maintain both speed and stability. At this level, the model requires enough memory and processing power to run smoothly, especially if you plan to use it for automation, APIs, or regular workloads.
- CPU: 8–16 Cores
A stronger CPU helps manage background processes and ensures smooth execution without delays.
- RAM: 16–32 GB
This range provides enough memory to load and run models reliably, reducing the chances of crashes or slowdowns.
- Storage: NVMe SSD
NVMe storage improves data access speed and reduces model loading time compared to standard SSDs.
- GPU: 12–24 GB VRAM
A GPU becomes important at this stage for faster inference and better overall performance.
With this setup, you can expect faster responses, stable execution, and the ability to handle multiple tasks efficiently. Many reliable VPS platforms, such as YouStable, provide configurations that match these requirements, making it easier to run LLMs without performance issues.
High End VPS Setup (Large Models / Production)
For large LLMs (30B+ parameters), you need a powerful VPS setup to ensure stable performance and avoid crashes during heavy workloads. These models require high memory, strong processing power, and GPU support to run efficiently, especially in production environments, AI applications, or continuous usage where multiple requests are handled at the same time.
High End Configuration Overview
| Component | Recommended Specs | Purpose |
| CPU | 16+ cores | Handles parallel tasks and system operations smoothly |
| RAM | 64–128 GB | Loads and runs large models without memory issues |
| Storage | 200+ GB NVMe | Ensures fast model loading and data access |
| GPU | 24–80 GB VRAM / Multi-GPU | Enables fast inference and supports large models |
This type of configuration is best suited for real world applications where performance, scalability, and reliability are critical.
Best LLM Models You Can Run on VPS
Choosing the right LLM depends on your VPS resources and your use case. Using a model that matches your system ensures smooth performance, faster responses, and avoids crashes or unnecessary slowdowns.
- Small Models: Fast and lightweight, best for testing and basic automation
- Medium Models: Balanced performance and accuracy, suitable for most real use cases
- Large Models: High quality output but require strong CPU, high RAM, and GPU support
Selecting the right model helps maintain stability and ensures your VPS runs efficiently without performance issues.
Software & Tools Required
Running LLMs efficiently requires a properly configured software environment, because even strong hardware can fail if the setup is not correct or optimized.
- Operating System (Linux recommended): Linux provides better stability, performance, and compatibility for most LLM tools and frameworks.
- Python environment: Most LLM frameworks depend on Python, so having the correct version and dependencies is essential for smooth execution.
- Docker (optional): Docker helps create a consistent environment, making deployment easier and preventing dependency conflicts.
- LLM tools (Ollama, Hugging Face): These tools allow you to download, manage, and run models efficiently on your VPS.
- GPU support (CUDA & drivers): If you are using a GPU, proper CUDA setup is required to enable acceleration and improve performance.
A clean and well configured setup ensures your LLM runs smoothly, avoids errors, and delivers consistent performance without interruptions.
Step by Step Guide: How to Run LLM Locally on VPS
Setting up an LLM on a VPS becomes straightforward when you follow a clear process. The goal is to prepare your server, install the required tools, and run a model in a stable environment so it works reliably without interruptions.
Step 1: Set Up Your VPS
Start by choosing a VPS with enough CPU, RAM, and storage based on your model size. A stable provider such as YouStable can help ensure consistent performance from the beginning, especially if you plan to run models continuously.
Step 2: Connect to Your Server (SSH)
Access your VPS securely using SSH from your terminal: ssh user@your-server-ip
Once connected, you will be able to control your server remotely.
Step 3: Update the System
Before installing anything, update your system to avoid compatibility issues: sudo apt update && sudo apt upgrade -y
This ensures all packages are up to date.
Step 4: Install Required Dependencies
Install essential tools like Python and pip: sudo apt install python3 python3-pip -y
These are required for most LLM frameworks and tools.
Step 5: Install LLM Tool (Example: Ollama)
Ollama is one of the easiest ways to run LLMs locally: curl -fsSL https://ollama.com/install.sh | sh
This installs the tool and prepares your environment.
Step 6: Download and Run a Model
Now you can download and run a model directly: ollama run llama2
The model will start loading and then accept prompts.
Step 7: Test the Model Output
Enter a simple prompt to confirm everything is working properly. If the model responds correctly, your setup is successful.
Step 8: Keep the Model Running
To ensure continuous operation, run the service in the background or use tools like tmux, screen, or system services. This prevents the model from stopping when you disconnect from SSH.
Following these steps ensures your LLM runs smoothly on a VPS with proper setup, stability, and minimal errors.
How to Access Your LLM
Once your LLM is running on the VPS, you can interact with it in multiple ways depending on how you plan to use it. Access methods are flexible, allowing you to connect your model with applications, automation tools, or direct interfaces for real world usage.
- Local API endpoints: You can send requests to your model using API calls, which is ideal for integrating with apps, scripts, or backend systems.
- Web based interfaces: Some tools provide a simple UI in your browser, making it easy to test prompts and interact with the model visually.
- Integration with apps or automation tools: You can connect your LLM with workflows, chatbots, or external services to automate tasks and build real applications.
With these access methods, your LLM becomes more than just a model running on a server, it turns into a usable system that can power real time applications and automation.
Best VPS for Running LLM
Choosing the right VPS is important because it directly affects performance, stability, and how smoothly your LLM runs under different workloads. A well balanced server ensures faster responses, fewer crashes, and better scalability as your usage grows.
What to Look for in a VPS
| Feature | Why It Matters |
| CPU & RAM | Strong processing power and sufficient memory ensure smooth execution and prevent slowdowns |
| NVMe Storage | Faster data access and quicker model loading compared to traditional storage |
| Uptime | Reliable uptime keeps your LLM running continuously without interruptions |
| Scalability | Allows you to upgrade resources easily as your workload increases |
A reliable provider like YouStable offers balanced VPS configurations that meet these requirements, making it easier to run LLMs efficiently without performance issues.
Common Issues and Fixes
While running LLMs on a VPS, you may face a few common problems, and most of them are related to resource limits or configuration issues. The good part is that these problems are usually easy to identify and fix once you understand the cause.
| Issue | Common Cause | Fix |
| Model not loading | Insufficient RAM | Upgrade RAM or use a smaller/quantized model |
| Slow performance | Weak CPU or no GPU acceleration | Use a better CPU or enable GPU support |
| Frequent crashes | System overload or high resource usage | Reduce workload or increase server resources |
| Access issues | Port blocked or firewall restrictions | Open required ports and check firewall settings |
Most issues can be resolved by adjusting your VPS resources, choosing the right model size, or fixing basic configuration settings.
How to Improve LLM Performance on VPS
Improving LLM performance on a VPS is not just about increasing resources, it’s about optimizing how your model runs. With the right approach, you can achieve faster responses, better stability, and efficient resource usage even without upgrading hardware immediately.
- Use quantized models (4-bit / 8-bit): These models consume less memory and run faster, making them ideal for limited resource environments.
- Choose the right model size: Running a model that matches your VPS capacity prevents slowdowns and avoids unnecessary load.
- Limit concurrent requests: Too many requests at once can overload your system, so controlling concurrency helps maintain stable performance.
- Use NVMe storage: Faster storage reduces model loading time and improves overall responsiveness.
- Monitor system usage regularly: Keeping track of CPU, RAM, and GPU usage helps identify bottlenecks before they cause issues.
A well optimized setup combined with a reliable VPS infrastructure, such as YouStable, can significantly improve performance and ensure smooth LLM execution without interruptions.
Local Setup vs VPS (Quick Comparison)
Choosing between a local system and a VPS depends on how you plan to use your LLM. A local setup is good for testing and learning, while a VPS provides better performance, stability, and continuous operation for real world usage.
| Setup | Best For | Limitations |
| Local System | Testing, learning, small models | Limited resources, no 24/7 uptime, slower performance |
| VPS | Automation, production, scaling | Higher cost but better performance and reliability |
For consistent performance and long term usage, a VPS is generally the more practical and scalable option.
When Should You Upgrade Your VPS?
You should upgrade your VPS when your current setup starts limiting performance, stability, or your ability to run models smoothly. As your workload grows or you move to larger models, your existing resources may no longer be enough.
- Slow response times: Your CPU or GPU is not powerful enough to handle the workload efficiently
- Frequent crashes or failures: Usually caused by insufficient RAM or VRAM
- Unable to run larger models: Your current hardware cannot support higher model sizes
- System overload with multiple tasks: Not enough cores or memory to handle concurrent requests
- High resource usage constantly: CPU, RAM, or GPU staying near maximum capacity
Upgrading at the right time ensures better speed, stability, and the ability to scale your LLM setup without interruptions.
FAQs
1. Can I run LLM locally on VPS without GPU?
Yes, it is possible to run small LLMs (1B–7B) on a VPS without GPU using CPU only. However, performance will be slower, especially during response generation. For better speed, stability, and support for larger models, a GPU with sufficient VRAM is strongly recommended.
2. How much does it cost to run LLM on VPS?
The cost depends on your server configuration. Basic VPS setups for small models are relatively affordable, while GPU based or high RAM servers for larger models can be more expensive. The advantage is that you avoid ongoing API costs and gain full control over usage and scaling.
3. Which LLM is best for running on VPS?
The best LLM depends on your VPS resources:
• Small models work well on low resource VPS for testing
• Medium models are ideal for automation and real applications
• Large models provide better accuracy but require strong GPU and high RAM
• Choosing a model that matches your server ensures smooth performance and avoids crashes.
4. Is running LLM on VPS better than using APIs?
Running LLM on VPS gives you more control, privacy, and long term cost efficiency compared to APIs. APIs are easier to start with, but they come with usage limits and recurring costs. A VPS setup is better for continuous workloads, custom workflows, and full control over your environment.
Conclusion
By now, it should be clear that running an LLM smoothly is less about the model itself and more about the environment you choose. Most issues like slow responses, crashes, or failed execution come from limited resources, not from the technology. Once you move to a VPS with the right configuration, those problems start to disappear, and your setup becomes stable, predictable, and much easier to manage.
The key is to match your server with your actual workload and grow gradually as your needs increase. When you properly run LLM locally on vps, you gain full control, better performance, and a setup that can handle real world tasks without interruptions. With a reliable VPS like YouStable and a well optimized environment, your LLM becomes fast, stable, and ready for consistent use.


