
Beste end-to-end monitoringtools Het zijn uniforme platforms die elke stap van een gebruikerstraject en de systemen daarachter volgen, waarbij synthetische tests en monitoring van echte gebruikers worden gecombineerd. (RUM), APM, logboeken, statistieken en traceringen.
Ze helpen DevOps/SRE-teams om problemen snel te detecteren, diagnosticeren en oplossen, SLA's/SLO's te beschermen en de digitale ervaring continu te verbeteren. Als uw stack browsers, API's, microservices, databases en clouds omvat, bieden end-to-end monitoringtools de enige bron van waarheid die u nodig hebt.
Deze gids rangschikt de 11 beste end-to-end monitoringtools van 2026, legt uit hoe je de juiste tool kiest en laat zien hoe je een realistische, schaalbare aanpak voor productieomgevingen opzet.
Wat is End-to-End Monitoring?
End-to-end monitoring volgt Live of gesimuleerde gebruikerstrajecten van de frontend naar de backend en de infrastructuurlagen.
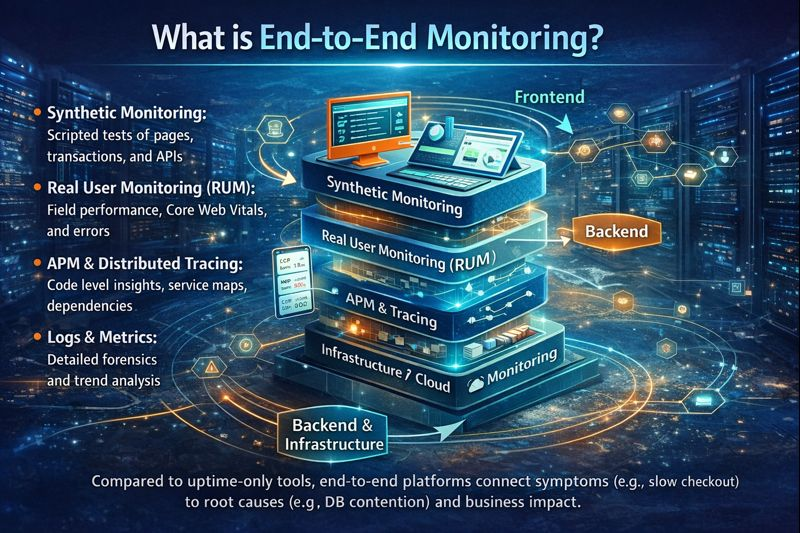
Een complete stapel combineert
- Synthetische monitoring: Gescripte tests van pagina's, transacties en API's vanuit meerdere regio's.
- Real User Monitoring (RUM): Realtime prestaties, Core Web Vitals en foutmeldingen voor daadwerkelijke gebruikers.
- APM en gedistribueerde tracering: Inzichten op codeniveau, serviceoverzichten, afhankelijkheden en latentie.
- Logboeken en statistieken: Gedetailleerde forensische analyse en trendanalyse.
- Infrastructuur-/cloudmonitoring: hosts, containers, Kubernetes, databases, serverless.
In tegenstelling tot tools die alleen de uptime meten, verbinden end-to-end platforms symptomen (bijvoorbeeld een trage checkout) met de onderliggende oorzaken (bijvoorbeeld databaseconflicten, een koude start of een falende afhankelijkheid) en de impact op de bedrijfsvoering.
Hoe kies je de beste end-to-end monitoringtool? in 2026?
- dekking: Synthetische monitoring, RUM, APM, logboeken, statistieken, tracering en infrastructuur/Kubernetes.
- OpenTelemetry-ondersteuning: Leverancieronafhankelijke instrumentatie voor toekomstbestendigheid.
- Hoofdoorzaak snelheid: AI/ML-ondersteunde correlatie, topologiekaarten en ruisonderdrukking.
- Dashboards en SLO's: Eenvoudig te maken, zakelijk aantrekkelijk en deelbaar.
- Alarm en oproepbaar: Flexibele routerings-, deduplicatie- en escalatiebeleidsregels.
- Schaalbaarheid en kosten: Transparante prijsstelling, gegevensbewaring en steekproefcontrole.
- Ecosysteem: integraties met CI/CD, cloud, incident management, en samenwerkingstools.
- Naleving en veiligheid: Gegevensopslaglocatie, RBAC, SSO en audit trails.
De 11 beste end-to-end monitoringtools in 2026
1. Gegevenshond
Wanneer trage applicaties, onverwachte fouten of onduidelijk systeemgedrag de gebruikerservaring en productiviteit beginnen te beïnvloeden, Datadog Het biedt duidelijkheid. Het is een geïntegreerd observatieplatform dat RUM, synthetische tests, APM, logboeken, infrastructuur en beveiliging omvat.
Door elke laag te monitoren, van frontend-interacties tot backend-services, API's, microservices en cloudinfrastructuur, worden alle gegevens gekoppeld voor een snelle analyse van de oorzaak van problemen.
Visuele dashboards, anomaliedetectie en flexibele waarschuwingen stellen teams in staat om problemen snel op te lossen, de prestaties te optimaliseren en soepele, betrouwbare en responsieve digitale processen te handhaven op cloud-native schaal.
- Beste voor: Snelgroeiende teams, cloud-native apps en bedrijven.
- Hoogtepunten: Servicemaps, Watchdog AIOps, CI-zichtbaarheid, Kubernetes-monitoring, SLO's.
- Voors: Diepgaande integraties, uitstekende gebruikerservaring, robuuste waarschuwingssystemen.
- nadelen: De prijs kan stijgen naarmate de hoeveelheid data en functies toeneemt.
2. Dynatrace
Trage applicaties, verborgen fouten en onduidelijk systeemgedrag kunnen de gebruikerservaring en bedrijfsvoering ongemerkt verstoren. Dynatrace lost dit op met AI-gestuurde end-to-end monitoring die automatisch elk component detecteert, afhankelijkheden in kaart brengt en de hoofdoorzaken opspoort met Davis AI.
Door frontend-, backend-, microservices- en infrastructuurdata met elkaar te verbinden, wordt de hoeveelheid meldingen verminderd en worden kritieke problemen juist duidelijk. Slimme dashboards, anomaliedetectie en geautomatiseerde inzichten stellen teams in staat om snel knelpunten op te lossen, de prestaties te optimaliseren en digitale ervaringen naadloos, betrouwbaar en responsief te houden in complexe cloudomgevingen.
- Beste voor: Bedrijven die behoefte hebben aan deterministische oorzaakbepaling en automatische instrumentatie.
- Hoogtepunten: Smartscape-topologie, Grail-datalakehouse, diepgaande analyse van Kubernetes.
- Voors: Sterke automatisering, nauwkeurige oorzaakanalyse.
- nadelen: Focus op grote ondernemingen; kosten en complexiteit kunnen hoog zijn voor kleine teams.
3. Nieuw relikwie
Wanneer digitale ervaringen vertragen of onverwachte fouten workflows verstoren, hebben teams helder inzicht nodig in elke laag van hun systemen. New Relic onderscheidt zich als dé oplossing. beste end-to-end monitoringtool, waarbij APM, real user monitoring (RUM), synthetische tests, logboeken, statistieken en traceringen worden samengebracht in één platform.
De intuïtieve dashboards en flexibele zoekopdrachten maken het eenvoudig om knelpunten te identificeren, prestatietrends te volgen en frontend-interacties te correleren met backend-processen.
Door bruikbare inzichten te bieden over de volledige stack, stelt New Relic teams in staat om applicaties te optimaliseren, een soepele gebruikerservaring te garanderen en betrouwbare, hoogwaardige digitale diensten te onderhouden zonder giswerk.
- Beste voor: Engineeringteams die op zoek zijn naar één uniforme gebruikersinterface voor de gehele stack.
- Hoogtepunten: NRQL-query's, gedistribueerde tracering, browser-/mobiele monitoring.
- Voors: Krachtige analyses, van oudsher royale gratis abonnementsniveaus.
- nadelen: Gebruiksafhankelijke prijsstelling vereist zorgvuldig beheer om de uitgaven te controleren.
4. Grafana Cloud
Wanneer het monitoren van meerdere systemen complex en versnipperd aanvoelt, vereenvoudigt Grafana Cloud de observeerbaarheid door metrics, logs, traces en synthetische tests in één tool te verenigen. managed platform.
Gebouwd op open standaarden zoals Prometheus, Loki, Tempo en k6, biedt het duidelijke visualisaties en dashboards die teams helpen problemen te signaleren, trends te analyseren en gegevens in de hele stack met elkaar te correleren.
Grafana Cloud maakt het eenvoudig om betrouwbare prestaties te behouden, workflows te optimaliseren en bruikbare inzichten te verkrijgen zonder handmatig infrastructuurbeheer.
- Beste voor: Teams die overstappen op OSS en OpenTelemetry met een managed backend.
- Hoogtepunten: k6 synthetische controles, vooraf gebouwde dashboards, SLO's, waarschuwingen.
- Voors: Open en flexibel, geweldige dashboards, sterke mogelijkheden voor kostenbeheersing.
- nadelen: Sommige zakelijke functies vereisen betaalde abonnementen; de installatie vereist nog steeds expertise.
5. Splunk Observability Cloud
Complexe systemen genereren enorme hoeveelheden data, waardoor het lastig is om de prestaties te volgen en problemen te identificeren. Splunk Observability Cloud pakt dit aan door metrics, logs en traces te combineren met krachtige analyses, waardoor teams een duidelijk, compleet overzicht van hun omgeving krijgen.
Ontworpen voor omgevingen met een hoge doorvoer en een focus op beveiliging, helpt het bij het snel detecteren van afwijkingen, het begrijpen van de oorzaken en het waarborgen van betrouwbare werking. Met flexibele dashboards, waarschuwingen en AI-gestuurde inzichten stelt Splunk teams in staat om de prestaties te optimaliseren, downtime te verminderen en soepele, schaalbare digitale ervaringen te garanderen.
- Beste voor: Bedrijven met complexe datavereisten en synergie met Splunk SIEM.
- Hoogtepunten: Geen opties voor het traceren van samples, krachtige loganalyse, door AI gegenereerde inzichten.
- Voors: Omvang en diepgang; gedegen forensisch onderzoek en correlatie.
- nadelen: De kosten en complexiteit kunnen hoog oplopen voor kleinere organisaties.
6. Elastische observeerbaarheid
Het monitoren van complexe applicaties kan lastig zijn zonder duidelijke inzichten. Elastic Observability vereenvoudigt dit door APM, logs, metrics en synthetische monitoring te combineren op het krachtige Elasticsearch-platform.
De flexibele architectuur stelt teams in staat om data efficiënt te analyseren, visualiseren en correleren, terwijl de levenscyclus van de index kostenefficiënt blijft. management houdt de opslag onder controle.
Met aanpasbare dashboards, waarschuwingen en machine learning-detectie helpt Elastic Observability teams prestatieproblemen op te sporen, processen te optimaliseren en soepele, betrouwbare systemen te onderhouden in web-, mobiele en cloudomgevingen.
- Beste voor: Teams die Elastic Stack al gebruiken en een geïntegreerde oplossing willen.
- Hoogtepunten: Beschikbaarheid/synthetische tests, RUM, APM-agents, detectie via machine learning.
- Voors: Krachtige zoekfunctie, zelf managed- of cloudopties.
- nadelen: Vereist afstemming om opslag en kosten op grote schaal te beheersen.
7. Cisco AppDynamics

Trage of mislukte transacties kunnen een directe impact hebben op de omzet en de gebruikerservaring. Cisco AppDynamics, de beste end-to-end monitoringtool Voor bedrijfskritische applicaties biedt het diepgaand inzicht in elke transactie, van frontend-interacties tot backend-services.
Het brengt omzetgevoelige processen in kaart, volgt de prestaties in realtime en signaleert knelpunten. Dit helpt teams bij het optimaliseren van de bedrijfsvoering, het garanderen van een soepele gebruikerservaring en het behalen van consistente bedrijfsresultaten in complexe applicatieomgevingen.
- Beste voor: Ondernemingen die behoefte hebben aan APM voor zakelijke transacties en een sterke governance.
- Hoogtepunten: Business iQ, monitoring van eindgebruikers, hybride zichtbaarheid.
- Voors: Uitstekend geschikt voor app-eigenaren en managers die resultaten willen bijhouden.
- nadelen: De complexiteit van licenties en implementatie kan groter zijn.
8. Schildwacht
Onduidelijke fouten, trage reacties en verborgen regressies kunnen de ontwikkeling vertragen en gebruikers hinderen. Sentry, een oplossing die primair voor ontwikkelaars is ontwikkeld, spoort frontend- en backendfouten op, bewaakt de prestaties en biedt gedetailleerd inzicht in de status van releases.
By verbindingskwesties Door specifieke commits te tonen en sessieherhalingen aan te bieden, kunnen teams snel problemen identificeren en oplossen. Hierdoor kunnen ontwikkelaars soepelere applicaties onderhouden, fouten met impact op gebruikers verminderen en de prestaties continu verbeteren met duidelijke, bruikbare gegevens in één intuïtief platform.
- Beste voor: Productteams optimaliseren de UX en lossen regressies snel op.
- Hoogtepunten: Foutopsporing aan de frontend, sessieherhalingen, prestaties.
- Voors: Uitstekend voor ontwikkelworkflows; overzichtelijke groepering van problemen.
- nadelen: Geen complete infrastructuurstack; combineer met metrics/infrastructuurmonitoring voor end-to-end-analyse.
9. Checkly
Onbetrouwbare webapplicaties of API-fouten kunnen de gebruikerservaring verstoren en ontwikkelcycli vertragen. Checkly biedt ontwikkelaarsgerichte synthetische monitoring, waarbij gebruik wordt gemaakt van op Playwright gebaseerde browsercontroles en API-asserties om kritieke processen continu te testen.
Geïntegreerd met CI / CD-pijpleidingenHet zorgt ervoor dat codeaanpassingen worden gevalideerd voordat ze de gebruikers bereiken. Met duidelijke waarschuwingen, gedetailleerde testresultaten en eenvoudige automatisering kunnen teams snel problemen opsporen en oplossen, consistente prestaties behouden en betrouwbare, naadloze digitale ervaringen leveren, terwijl de downtime wordt verminderd en de algehele applicatiekwaliteit wordt verbeterd.
- Beste voor: Engineeringteams automatiseren synthetische end-to-end-controles in CI/CD.
- Hoogtepunten: Scripts voor toneelschrijvers, API-controles, op Git gebaseerde workflows, waarschuwingen.
- Voors: Eerst coderen, dan is het makkelijk om versies te beheren en te controleren.
- nadelen: Moet worden gekoppeld aan RUM/APM voor volledig inzicht in de stack.
10. Sematext-wolk
Het behouden van een soepele werking applicatie prestaties Monitoring op verschillende apparaten en locaties kan een uitdaging vormen voor groeiende teams. Sematext Cloud biedt een alles-in-één oplossing die synthetische monitoring, RUM, logboeken, statistieken en infrastructuurbewaking combineert in een betaalbaar pakket.
Het biedt heldere inzichten, bruikbare waarschuwingen en een eenvoudige installatie, waardoor mkb's en middelgrote teams snel knelpunten kunnen identificeren, prestaties kunnen optimaliseren en betrouwbare digitale ervaringen kunnen garanderen zonder meerdere tools of complexe integraties te hoeven beheren.
- Beste voor: Teams die op zoek zijn naar een goede balans tussen functionaliteit en prijs.
- Hoogtepunten: Website- en API-monitoring, logbestanden, container-/K8s-monitoring.
- Voors: Eenvoudige prijsstelling, snelle installatie, goede dekking.
- nadelen: Minder geavanceerde functies dan de toppakketten.
11. Honingraat
Het beheren van complexe microservices en het opsporen van verborgen prestatieproblemen kan een enorme uitdaging vormen voor SRE- en DevOps-teams. Honeycomb pakt dit aan met op gebeurtenissen gebaseerde observability en querying met een hoge kardinaliteit, waardoor snelle oorzaakanalyse mogelijk is in complexe systemen.
Dankzij krachtige functies zoals BubbleUp, trace-analyse en OpenTelemetry-ondersteuning kunnen onbekende problemen sneller en nauwkeuriger worden opgespoord.
Hoewel Honeycomb geen complete alles-in-één oplossing is, biedt de combinatie met RUM of synthetische monitoring uitgebreide inzichten van begin tot eind. Dit helpt teams bij het debuggen, optimaliseren en onderhouden van betrouwbare, goed presterende applicaties met vertrouwen.
- Beste voor: Geavanceerde SRE/DevOps-teams met uitgebreide traceerbehoeften.
- Hoogtepunten: BubbleUp, trace-analyse, OTel-ondersteuning, krachtige zoekopdrachten.
- Voors: Snelle incidentanalyse, ideaal voor onbekende onbekenden.
- nadelen: Minder traditioneel "alles-in-één"; combineer met synthetische stoffen/RUM voor volledige end-to-end verwerking.
Snelle vergelijkingssnapshot
- Snelle start en breedste ecosysteem: Datadog, New Relic
- AI-hoofdoorzaak op bedrijfsniveau: Dynatrace, Splunk Observability
- Open, op OSS afgestemde stack: Grafana Cloud, Elastic Observability
- APM voor zakelijke transacties: Cisco AppDynamics
- Frontendfout + prestaties: Schildwacht
- Code first synthetics: checkly
- Waardegerichte alleskunner: Sematext-wolk
- Geavanceerde traceeranalyse: honingraat
End-to-end monitoring voor een WordPress + WooCommerce webwinkel - Praktische opstelling
- Synthetisch: Script een browsernavigatie van home > categorie > product > toevoegen aan winkelwagen > afrekenen, vanuit meer dan 5 regio's.
- RUM: Houd de belangrijkste webstatistieken (LCP, INP, CLS), geografische locaties, apparaten en belangrijke paden (zoeken, afrekenen) bij.
- MPA: Instrument PHP en kritieke services (cache, database, betalingsgateways) met OpenTelemetry-agents.
- Infra: NGINX monitoren/Apache, PHP-FPM, MySQL, Redis en Kubernetes-nodes/pods, indien van toepassing.
- logs: Centraliseer NGINX- en applicatielogboeken en schakel gestructureerde logboekregistratie in voor doorzoekbaarheid.
- Alarmering: SLO's voor beschikbaarheid en laadtijd van de p95-pagina; oproeproutering naar Slack/Teams met incidenttemplates.
Voorbeeld van een synthetische test met JavaScript in Playwright-stijl (werkt in tools zoals Checkly):
import { test, expect } from '@playwright/test';
test('WooCommerce checkout flow', async ({ page }) => {
await page.goto('https://yourstore.com');
await expect(page).toHaveTitle(/Your Store/i);
await page.click('text=Shop');
await page.click('text=Add to cart', { timeout: 15000 });
await page.click('text=Cart');
await page.click('text=Proceed to checkout');
await page.fill('#billing_email', 'synthetic@example.com');
await page.fill('#billing_first_name', 'Synth');
await page.fill('#billing_last_name', 'Check');
await page.click('#place_order');
await expect(page.locator('text=Order received')).toBeVisible({ timeout: 30000 });
});Combineer dit met RUM voor echte gebruikers, APM voor PHP/database-knelpunten en logbestanden voor foutanalyse. Stel SLO's in (bijv. 99.9% uptime, p95 checkout < 3s) en waarschuwingen over de verbruikssnelheid om degradaties vroegtijdig te detecteren.
Beste praktijken voor monitoring in 2026
- Neem OpenTelemetry in gebruik: Eenmalig een instrument aanschaffen, later zonder aanpassingen van leverancier wisselen.
- Gebruiker meten centrale resultaten: Geef prioriteit aan essentiële webgegevens en belangrijke transacties.
- Definieer SLO's met foutbudgetten: Stem de prioriteiten van de technische afdeling af op de bedrijfsdoelstellingen.
- Automatiseer in CI/CD: Voer synthetische controles uit op elke implementatie en blokkeer risicovolle releases.
- Gegevens over de juiste afmetingen: Gebruik steekproeven, bewaarbeleid en analyseniveaus om de kosten te beheersen.
- Unify-meldingen: Verminder ruis met correlatie en verstuur bruikbare, gerichte waarschuwingen.
- Veilig ontworpen: Zorg voor SSO, RBAC, gegevensmaskering en auditlogs in alle tools.
Waarom monitoring combineren met een snelle, stabiele infrastructuur? – Hosting is belangrijk
Monitoring laat zien waar de prestaties haperen; goede hosting voorkomt veel van die haperingen. Op een geoptimaliseerde infrastructuur zie je minder trage query's, een snellere TTFB (Time To First Byte) en stabielere Core Web Vitals.
At YouStableonze geoptimaliseerde WordPress hostingSSD/NVMe-opslag en proactieve beveiligingsmaatregelen zorgen ervoor dat uw monitoringgegevens de juiste trends vertonen: snellere pagina's, minder incidenten en tevredener gebruikers.
Als je overstapt naar een moderne observatiestack, overweeg dan om deze af te stemmen op een schaalbare oplossing. hosting planWe kunnen u helpen met het benchmarken van TTFB en het afstemmen van de software. PHP-FPM/MySQLEn stel realistische SLO's vast voordat je een nieuwe tool uitrolt. Het resultaat: overzichtelijkere dashboards en minder valse alarmen.
Veelgestelde vragen
Wat is het verschil tussen observeerbaarheid en monitoring?
Monitoring registreert bekende omstandigheden en KPI's (bijv. uptime, fouten). Observability stelt u in staat onbekende problemen te onderzoeken met behulp van logs, metrics en traces. End-to-end tools bieden steeds vaker beide: proactieve monitoring én diepgaand, ad-hoc onderzoek.
Heb ik zowel synthetische monitoring als RUM nodig?
Ja. Synthetische monitoring controleert kritieke datastromen vanuit vaste locaties volgens een vast schema, waardoor problemen worden opgespoord voordat gebruikers ze ervaren. RUM registreert de daadwerkelijke prestaties op verschillende apparaten, netwerken en regio's. Samen bieden ze een volledig overzicht van de digitale ervaring.
Welke tool is het beste voor WordPress of WooCommerce?
Voor een alles-in-één oplossing zijn Datadog, New Relic of Grafana Cloud sterke opties. Als je de voorkeur geeft aan een modulaire aanpak, combineer dan Checkly (synthetische fouten) + Sentry (frontend/backend fouten) + Grafana Cloud (metrics/logs/traces). Host op een geoptimaliseerde infrastructuur zoals... YouStable om betere basisprestaties te ontsluiten.
Hoe stel ik SLO's in voor mijn app?
Begin met indicatoren die van invloed zijn op de gebruiker: beschikbaarheid van cruciale routes en p95/p99-latentie. Gebruik historische gegevens om realistische doelen te stellen (bijv. 99.9% succesvolle afrekening, p95 < 3s). Houd foutbudgetten bij en waarschuw voor de snelheid waarmee fouten worden verwerkt, zodat problemen prioriteit krijgen voordat klanten er last van ondervinden.
Is OpenTelemetry verplicht in 2026?
Verplicht? Nee? Praktisch gezien? Ja? OTel standaardiseert telemetrie in alle talen en bij alle leveranciers, vermindert vendor lock-in en versnelt instrumentatie. De meeste toonaangevende tools in deze lijst ondersteunen OpenTelemetry, waardoor het een slimme standaardkeuze is voor nieuwe services.

