Les lenteurs de réponse, les plantages aléatoires et les défaillances des modèles au moment crucial sont souvent dues à des ressources système locales limitées. Les modèles LLM modernes nécessitent une stabilité RAM, une puissance de traitement élevée et une disponibilité constante, que la plupart des configurations personnelles ne peuvent pas gérer efficacement, ce qui entraîne des performances instables et des problèmes d'exécution fréquents.
Une solution plus fiable consiste à exécuter LLM localement sur un VPS, où des ressources dédiées et une meilleure disponibilité garantissent un environnement stable. Cette configuration améliore les performances, réduit les pannes et prend en charge les charges de travail réelles. Avec une configuration adéquate, votre instance LLM fonctionne de manière fluide, constante et sans interruptions inutiles.
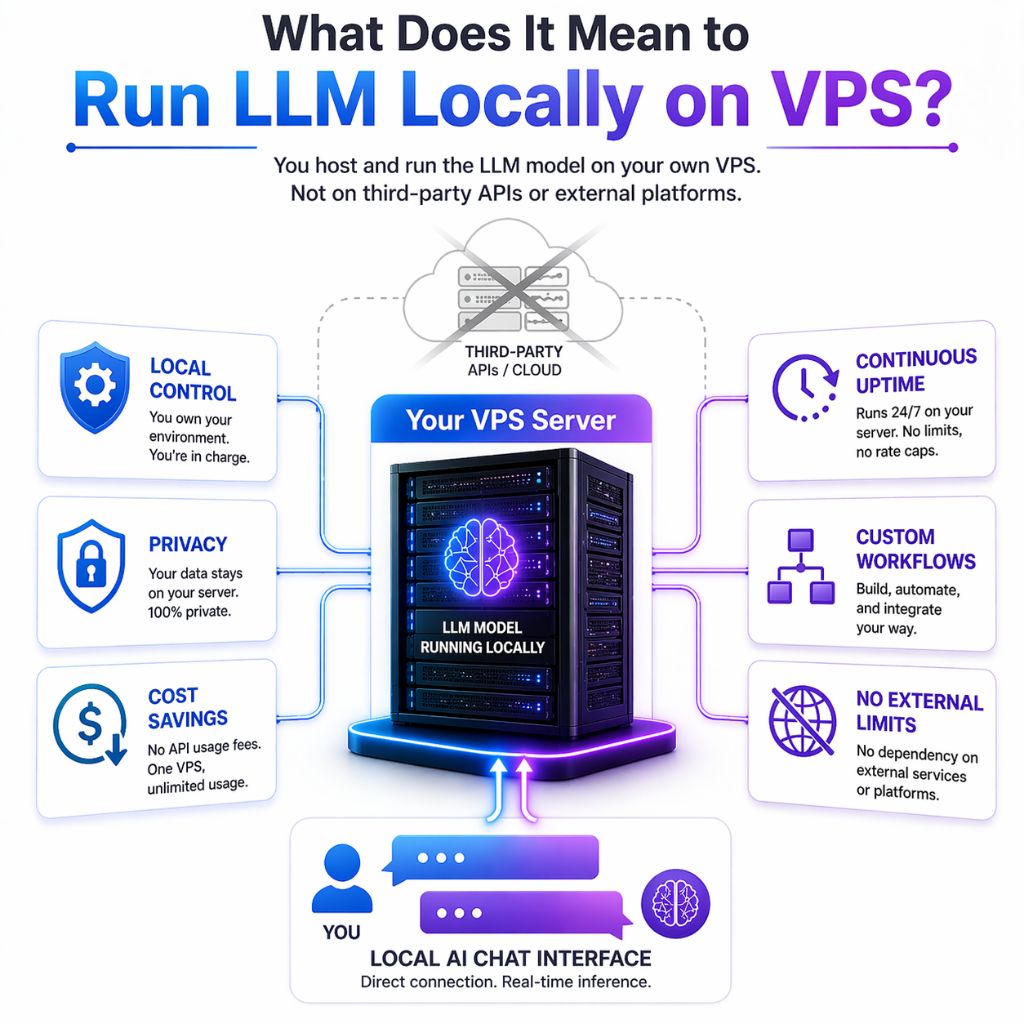
Que signifie exécuter LLM localement sur un VPS ?
L'exécution d'un LLM localement sur un VPS signifie que vous hébergez et exécutez le modèle sur votre propre serveur, sans dépendre d'API tierces ni de plateformes externes. Bien que le serveur soit distant, il fonctionne comme votre système personnel : vous contrôlez l'installation, la configuration et l'utilisation du modèle sans aucune limitation externe.
Cette configuration vous offre un contrôle total sur les performances, la confidentialité et les coûts.
Vous pouvez manage Sécurisez vos données, évitez les frais d'API récurrents et exécutez le modèle en continu pour l'automatisation ou des applications concrètes.
Il est particulièrement utile lorsque vous souhaitez une production stable, des flux de travail personnalisables et un environnement fiable qui ne dépend pas de services externes ni de limites d'utilisation.
Pourquoi utiliser un VPS plutôt qu'un système local ?
Un système local peut Il gère les tests de base, mais ses limites s'accumulent rapidement lorsqu'on exécute régulièrement des LLM. La plupart des ordinateurs personnels peinent à gérer des tâches limitées. RAM, moyenne CPUL'absence de GPU dédié entraîne des lenteurs, des plantages et des échecs d'exécution. De plus, tout dépend de l'activité de votre appareil ; toute coupure ou interruption interrompt donc vos flux de travail.
Un VPS offre un environnement beaucoup plus fiable et évolutif pour l'exécution de LLM. Il fonctionne en continu, propose des ressources dédiées et permet des mises à niveau. CPU, RAMou du stockage à mesure que votre charge de travail augmente. Cela rend votre configuration plus stable, plus rapide et adaptée à une utilisation réelle. Choisir une plateforme VPS fiable comme YouStable Améliore encore les performances en réduisant les temps d'arrêt et en gérant des charges de travail importantes sans interruption.
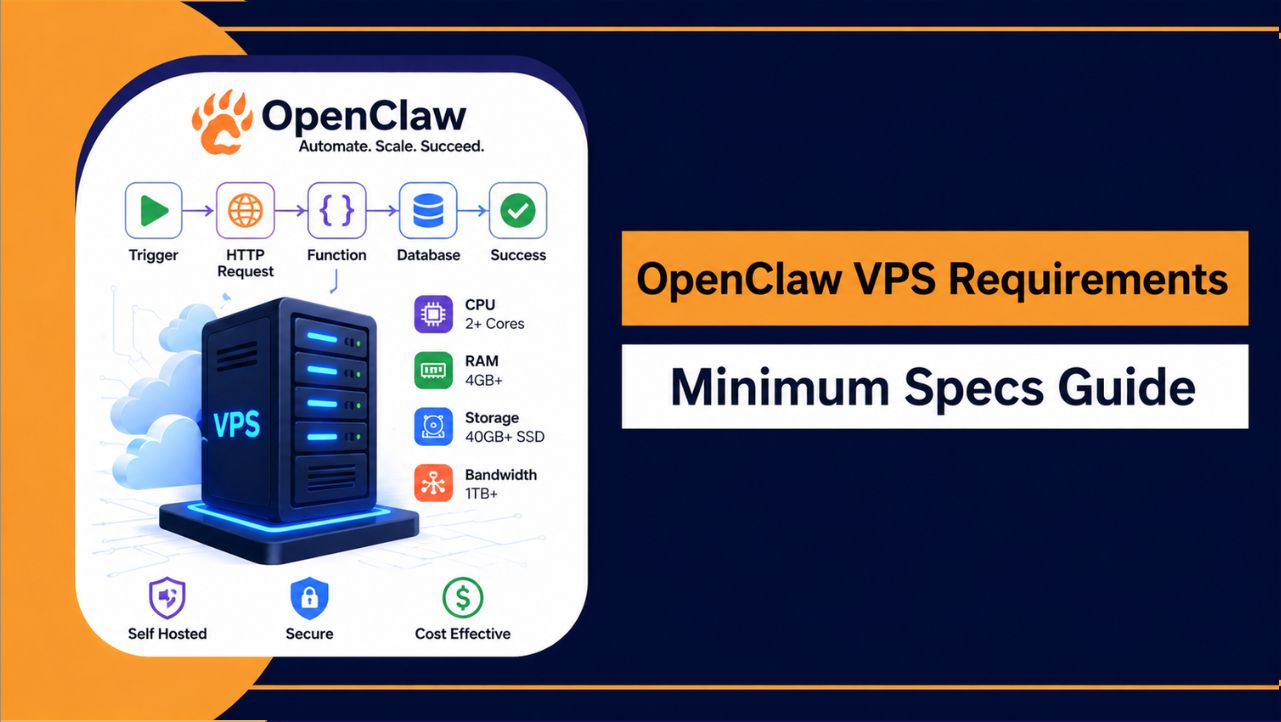
Configuration minimale requise pour un VPS permettant d'exécuter LLM
Si vous débutez Pour les modèles linéaires à grande échelle (LLM) ou les modèles plus petits (environ 1 à 7 milliards de paramètres), un serveur haut de gamme n'est pas nécessaire. Une configuration VPS basique suffit pour exécuter ces modèles à des fins de test, d'apprentissage et pour des tâches d'automatisation légères. Cependant, même les petits modèles requièrent un environnement stable ; il est donc important de choisir la configuration minimale appropriée afin d'éviter les ralentissements ou les plantages inattendus.
Explication des exigences de base
- CPU: 4 à 8 cœurs
Un processeur multicœur moderne CPU aide manage Processus système et exécution du modèle. Bien que les LLM s'appuient davantage sur le GPU pour la vitesse, un bon CPU garantit le bon fonctionnement du système sans goulots d'étranglement.
- AM : 8–16 Go
RAM C'est essentiel car le modèle doit être chargé en mémoire lors de son exécution. Avec moins de 8 Go, vous risquez de rencontrer des problèmes au démarrage ou des plantages. 16 Go offrent une meilleure stabilité et des performances plus fluides.
- Stockage : SSD de 50 Go (recommandé)
Un stockage rapide comme un SSD garantit un chargement plus rapide des modèles et un meilleur accès aux données. Un disque dur classique peut ralentir considérablement le processus, notamment lors de la manipulation de fichiers volumineux.
- GPU : optionnel (4 à 8 Go V)RAM (si disponible)
Un GPU n'est pas nécessaire pour les petits modèles, mais il peut améliorer considérablement la vitesse de réponse. Sans GPU, le modèle fonctionnera sur CPU, ce qui est plus lent mais reste utilisable pour les tâches de base.
Ce que vous pouvez attendre de cette configuration
Cette configuration convient bien pour :
- Apprendre comment fonctionnent les LLM
- Modèles de petite taille en fonctionnement
- Invites et flux de travail de test
- Tâches d'automatisation de base
Cependant, les performances seront limitées. Vous constaterez peut-être des temps de réponse plus longs, surtout sans accélération GPU. Cette configuration n'est pas idéale pour gérer plusieurs requêtes simultanément ou exécuter des modèles volumineux.
Configuration VPS recommandée pour des performances optimales
Pour les LLM de taille moyenne Avec environ 7 à 13 milliards de paramètres, une configuration VPS équilibrée est essentielle pour garantir à la fois vitesse et stabilité. À ce niveau, le modèle requiert suffisamment de mémoire et de puissance de traitement pour un fonctionnement optimal, notamment pour l'automatisation, les API ou les charges de travail régulières.
- CPU: 8 à 16 cœurs
Un plus fort CPU aide manage Les processus en arrière-plan garantissent une exécution fluide et sans retard.
- RAM: 16-32 Go
Cette plage de capacités offre une mémoire suffisante pour charger et exécuter les modèles de manière fiable, réduisant ainsi les risques de plantages ou de ralentissements.
- Stockage : SSD NVMe
Le stockage NVMe améliore la vitesse d'accès aux données et réduit le temps de chargement des modèles par rapport aux SSD standard.
- GPU : 12–24 Go VRAM
À ce stade, le GPU devient important pour une inférence plus rapide et de meilleures performances globales.
Avec cette configuration, vous pouvez vous attendre à des réponses plus rapides, une exécution stable et la capacité de gérer efficacement plusieurs tâches. De nombreuses plateformes VPS fiables, telles que… YouStable, fournir des configurations qui correspondent à ces exigences, facilitant ainsi l'exécution des LLM sans problèmes de performance.
Configuration VPS haut de gamme (Modèles importants / Production)
Pour les grands LLM (Plus de 30 milliards de paramètres) : une configuration VPS puissante est indispensable pour garantir des performances stables et éviter les plantages lors de fortes charges de travail. Ces modèles nécessitent une grande quantité de mémoire, une puissance de traitement élevée et la prise en charge d’un GPU pour fonctionner efficacement, notamment en production, pour les applications d’IA ou en cas d’utilisation continue avec de nombreuses requêtes simultanées.
Aperçu de la configuration haut de gamme
| Composant | Caractéristiques recommandées | Interet |
| CPU | 16+ cœurs | Gère les tâches parallèles et les opérations système sans problème. |
| RAM | 64 - 128 GB | Charge et exécute des modèles volumineux sans problème de mémoire. |
| Stockage | SSD NVMe de plus de 200 Go | Garantit un chargement rapide des modèles et un accès rapide aux données |
| GPU | 24–80 Go VRAM / Multi-GPU | Permet une inférence rapide et prend en charge les grands modèles |
Ce type de configuration est parfaitement adapté aux applications concrètes où les performances, l'évolutivité et la fiabilité sont essentielles.
Meilleurs modèles LLM que vous pouvez exécuter sur un VPS
Choisir le bon modèle de ligne de commande (LLM) dépend des ressources de votre VPS et de votre utilisation. Un modèle adapté à votre système garantit des performances optimales, des temps de réponse plus rapides et évite les plantages et les ralentissements inutiles.
- Petits modèles : Rapide et léger, idéal pour les tests et l'automatisation de base
- Modèles moyens : Performances et précision équilibrées, adaptées à la plupart des cas d'utilisation réels
- Modèles de grande taille : Production de haute qualité, mais nécessite une forte intensité. CPU, haute RAMet la prise en charge des GPU
Choisir le bon modèle contribue à maintenir la stabilité et garantit un fonctionnement efficace de votre VPS, sans problèmes de performance.
Logiciels et outils requis
Le bon fonctionnement des LLM nécessite un environnement logiciel correctement configuré, car même un matériel performant peut tomber en panne si la configuration n'est pas correcte ou optimisée.
- Système d'exploitation (Linux recommandé) : Linux offre une meilleure stabilité, de meilleures performances et une meilleure compatibilité pour la plupart des outils et frameworks LLM.
- Environnement Python : La plupart des frameworks LLM dépendent de Python ; il est donc essentiel de disposer de la version et des dépendances correctes pour un bon fonctionnement.
- Docker (facultatif) : Docker contribue à créer un environnement cohérent, facilitant le déploiement et évitant les conflits de dépendances.
- Outils LLM (Ollama, Hugging Face) : Ces outils vous permettent de télécharger, manageet exécuter efficacement des modèles sur votre VPS.
- Prise en charge du GPU (CUDA et pilotes) : Si vous utilisez un GPU, une configuration CUDA correcte est nécessaire pour activer l'accélération et améliorer les performances.
Une configuration propre et bien paramétrée garantit le bon fonctionnement de votre LLM, évite les erreurs et assure des performances constantes sans interruption.
Guide étape par étape : Comment exécuter LLM en local sur un VPS
Mise en place d'un LLM sur un VPS Cela devient simple lorsqu'on suit une procédure claire. L'objectif est de préparer son serveur, d'installer les outils nécessaires et d'exécuter un modèle dans un environnement stable afin qu'il fonctionne de manière fiable et sans interruption.
Étape 1 : Configurer votre VPS
Commencez par choisir un VPS suffisamment performant. CPU, RAMet un espace de stockage adapté à la taille de votre modèle. Un fournisseur fiable tel que YouStable peut contribuer à garantir des performances constantes dès le départ, notamment si vous prévoyez d'exécuter les modèles en continu.
Étape 2 : Connectez-vous à votre serveur (SSH)
Accédez à votre VPS en toute sécurité via SSH Depuis votre terminal : ssh utilisateur@votre-adresse-ip
Une fois connecté, vous pourrez contrôler votre serveur à distance.
Étape 3 : Mettre à jour le système
Avant toute installation, mettez à jour votre système pour éviter les problèmes de compatibilité : sudo apt update && sudo apt upgrade -y
Cela garantit que tous les packages sont à jour.
Étape 4 : Installer les dépendances requises
Installez les outils essentiels comme Python et pip : sudo apt install python3 python3-pip -y
Ces éléments sont requis par la plupart des cadres et outils LLM.
Étape 5 : Installer l’outil LLM (Exemple : Ollama)
Ollama est l'un des moyens les plus simples d'exécuter des LLM en local : curl -fsSL https://ollama.com/install.sh | sh
Cela installe l'outil et prépare votre environnement.
Étape 6 : Télécharger et exécuter un modèle
Vous pouvez désormais télécharger et exécuter un modèle directement : ollama run llama2
Le modèle commencera à se charger puis acceptera les instructions.
Étape 7 : Tester les résultats du modèle
Saisissez une question simple pour confirmer que tout fonctionne correctement. Si le modèle répond correctement, votre installation est réussie.
Étape 8 : Maintenir le modèle en fonctionnement
Pour garantir un fonctionnement continu, exécutez le service en arrière-plan ou utilisez des outils comme tmux, screen ou les services système. Cela empêche le modèle de s'arrêter lorsque vous vous déconnectez. SSH.
Le respect de ces étapes garantit le bon fonctionnement de votre LLM sur un VPS, avec une configuration appropriée, une stabilité optimale et un minimum d'erreurs.
Comment accéder à votre LLM
Une fois votre LLM exécuté sur le VPS, vous pouvez interagir avec lui de multiples façons selon votre utilisation. Les méthodes d'accès sont flexibles et vous permettent de connecter votre modèle à des applications, des outils d'automatisation ou des interfaces directes pour une utilisation concrète.
- Points de terminaison de l'API locale : Vous pouvez envoyer des requêtes à votre modèle via des appels d'API, ce qui est idéal pour l'intégration avec des applications, des scripts ou des systèmes backend.
- Interfaces Web : Certains outils proposent une interface utilisateur simple dans votre navigateur, ce qui facilite le test des invites et l'interaction visuelle avec le modèle.
- Intégration avec des applications ou des outils d'automatisation : Vous pouvez connecter votre LLM à des flux de travail, des chatbots ou des services externes pour automatiser les tâches et créer de véritables applications.
Grâce à ces méthodes d'accès, votre LLM devient bien plus qu'un simple modèle exécuté sur un serveur ; il se transforme en un système utilisable capable d'alimenter des applications en temps réel et l'automatisation.
Meilleur VPS pour exécuter LLM
Choisir le bon VPS est essentiel car cela influe directement sur les performances, la stabilité et le bon fonctionnement de votre application LLM, quelle que soit la charge de travail. Un serveur bien équilibré garantit des temps de réponse plus rapides, moins de plantages et une meilleure évolutivité à mesure que votre utilisation augmente.
Que rechercher dans un VPS ?
| Caractéristique | Pourquoi ça compte |
| CPU & RAM | Une puissance de traitement élevée et une mémoire suffisante garantissent un fonctionnement fluide et évitent les ralentissements. |
| Stockage NVMe | Accès aux données et chargement des modèles plus rapides qu'avec un stockage traditionnel |
| Uptime | Une disponibilité fiable garantit le fonctionnement continu de votre LLM sans interruption. |
| Évolutivité | Vous permet de mettre à niveau facilement vos ressources à mesure que votre charge de travail augmente. |
Un fournisseur fiable comme YouStable propose des configurations VPS équilibrées qui répondent à ces exigences, facilitant ainsi l'exécution efficace de LLM sans problèmes de performance.
Problèmes courants et correctifs
Lors de l'exécution de LLM sur un VPSVous pourriez rencontrer quelques problèmes courants, la plupart liés à des limites de ressources ou à des problèmes de configuration. Heureusement, ces problèmes sont généralement faciles à identifier et à résoudre une fois leur cause comprise.
| Question | Cause commune | Fixer |
| Modèle non chargé | Insuffisant RAM | Mise à niveau RAM ou utiliser un modèle plus petit/quantifié |
| Un ralentissement des performances | Faible CPU ou sans accélération GPU | Utilisez un meilleur CPU ou activer la prise en charge du GPU |
| Plantages fréquents | Surcharge du système ou utilisation élevée des ressources | Réduire la charge de travail ou augmenter les ressources du serveur |
| Problèmes d'accès | Port bloqué ou restrictions de pare-feu | Ouvrez les ports nécessaires et vérifiez les paramètres du pare-feu. |
La plupart des problèmes peuvent être résolus en ajustant les ressources de votre VPS, en choisissant la taille de modèle appropriée ou en corrigeant les paramètres de configuration de base.
Comment améliorer les performances de LLM sur un VPS
Amélioration des performances LLM L'utilisation d'un VPS ne se limite pas à l'augmentation des ressources ; il s'agit d'optimiser le fonctionnement de votre modèle. Avec la bonne approche, vous pouvez obtenir des temps de réponse plus rapides, une meilleure stabilité et une utilisation efficace des ressources, même sans mise à niveau matérielle immédiate.
- Utilisez des modèles quantifiés (4 bits / 8 bits) : Ces modèles consomment moins de mémoire et fonctionnent plus rapidement, ce qui les rend idéaux pour les environnements aux ressources limitées.
- Choisissez la bonne taille de modèle : L'utilisation d'un modèle adapté à la capacité de votre VPS permet d'éviter les ralentissements et les charges inutiles.
- Limiter les requêtes simultanées : Un trop grand nombre de requêtes simultanées peut surcharger votre système ; contrôler la concurrence permet donc de maintenir des performances stables.
- Utilisez le stockage NVMe : Un stockage plus rapide réduit le temps de chargement des modèles et améliore la réactivité globale.
- Surveillez régulièrement l'utilisation du système : Garder une trace de CPU, RAMet l'utilisation du GPU permet d'identifier les goulots d'étranglement avant qu'ils ne causent des problèmes.
Une configuration bien optimisée associée à une infrastructure VPS fiable, telle que YouStable, peut améliorer considérablement les performances et garantir une exécution LLM fluide et sans interruption.
Configuration locale vs VPS (Comparaison rapide)
Le choix entre un système local et un VPS dépend de l'utilisation que vous prévoyez pour votre LLM. Une configuration locale convient aux tests et à l'apprentissage, tandis qu'un VPS offre de meilleures performances, une plus grande stabilité et un fonctionnement continu pour une utilisation en production.
| installation | Idéal pour | Limites |
| Système local | Tests, apprentissage, petits modèles | Ressources limitées, disponibilité non assurée 24h/24 et 7j/7, performances réduites |
| VPS | Automatisation, production, mise à l'échelle | Coût plus élevé, mais meilleures performances et fiabilité |
Pour des performances constantes et une utilisation à long terme, un VPS est généralement l'option la plus pratique et la plus évolutive.
Quand devriez-vous mettre à niveau votre VPS ?
Il est conseillé de mettre à niveau votre VPS lorsque votre configuration actuelle commence à limiter les performances, la stabilité ou la fluidité d'exécution des modèles. À mesure que votre charge de travail augmente ou que vous passez à des modèles plus volumineux, vos ressources actuelles risquent de ne plus suffire.
- Temps de réponse lents : Votre CPU ou le GPU n'est pas suffisamment puissant pour gérer efficacement la charge de travail
- Pannes ou défaillances fréquentes : Généralement causé par une insuffisance RAM ou VRAM
- Impossible d'exécuter des modèles plus volumineux : Votre matériel actuel ne prend pas en charge les modèles de taille supérieure.
- Surcharge du système avec de multiples tâches : Pas assez de cœurs ou de mémoire pour gérer les requêtes simultanées
- Utilisation élevée et constante des ressources : CPU, RAMou le GPU restant proche de sa capacité maximale
La mise à niveau au bon moment garantit une meilleure vitesse, une plus grande stabilité et la possibilité de faire évoluer votre configuration LLM sans interruption.
Questions fréquentes
1. Puis-je exécuter LLM localement sur un VPS sans GPU ?
OuiIl est possible d'exécuter de petits LLM (1 à 7 octets) sur un VPS sans GPU en utilisant CPU uniquement. Cependant, les performances seront moindres, notamment lors de la génération des réponses. Pour une meilleure vitesse, une stabilité accrue et la prise en charge de modèles plus volumineux, un GPU avec une V suffisante est recommandé.RAM est fortement recommandé.
2. Combien coûte l'exécution de LLM sur un VPS ?
Le coût dépend de la configuration de votre serveur. Les configurations VPS de base pour les petits budgets sont relativement abordables, tandis que les configurations avec GPU ou haut de gamme sont plus coûteuses. RAM Les serveurs dédiés aux modèles plus importants peuvent s'avérer plus coûteux. L'avantage réside dans l'absence de frais d'API récurrents et dans un contrôle total sur l'utilisation et la mise à l'échelle.
3. Quel LLM est le mieux adapté à une exécution sur un VPS ?
Le meilleur LLM dépend des ressources de votre VPS :
• Les petits modèles fonctionnent bien sur un VPS à faibles ressources pour les tests
• Les modèles de taille moyenne sont idéaux pour l'automatisation et les applications réelles.
• Les modèles de grande taille offrent une meilleure précision, mais nécessitent un GPU puissant et une haute résolution. RAM
• Choisir un modèle adapté à votre serveur garantit un fonctionnement optimal et évite les plantages.
4. Est-il préférable d'exécuter LLM sur un VPS plutôt que d'utiliser des API ?
L'exécution de LLM sur un VPS offre davantage de contrôle, de confidentialité et une meilleure rentabilité à long terme par rapport aux API. Les API sont plus faciles à prendre en main, mais elles imposent des limites d'utilisation et des coûts récurrents. Une configuration VPS est plus adaptée aux charges de travail continues, aux flux de travail personnalisés et à un contrôle total de votre environnement.
Conclusion
Il devrait désormais être clair que le bon fonctionnement d'un LLM dépend moins du modèle lui-même que de l'environnement choisi. La plupart des problèmes, tels que les lenteurs, les plantages ou les échecs d'exécution, sont dus à des ressources limitées, et non à la technologie. En migrant vers un VPS correctement configuré, ces problèmes disparaissent progressivement et votre installation devient stable, prévisible et bien plus simple à gérer. manage.
L'essentiel est d'adapter la taille de votre serveur à votre charge de travail réelle et de l'augmenter progressivement en fonction de vos besoins. En exécutant correctement LLM en local sur un VPS, vous bénéficiez d'un contrôle total, de meilleures performances et d'une configuration capable de gérer des tâches réelles sans interruption. Avec un VPS fiable comme YouStable Dans un environnement bien optimisé, votre LLM devient rapide, stable et prêt pour une utilisation continue.