
基础设施监控工具 这些平台能够收集、关联和可视化跨服务器、网络、数据库、容器和云服务的指标、日志和跟踪信息,以检测问题并维护 SLA。
2026 年最佳工具将可观测性与 AI 驱动的洞察、自动化发现和 Kubernetes 原生支持相结合,从而缩短平均修复时间 (MTTR) 并实现跨混合云和多云环境的扩展。如果您运行的是现代工作负载,那么选择合适的基础设施监控工具将是您在 2026 年做出的投资回报率最高的决策之一。
在这份深度指南中,我评估了适用于云端、本地部署和混合架构的 11 种最佳方案,重点关注可靠性、可见性和总体拥有成本。无论您是中小企业还是大型企业 SRE 团队,这份对比报告都能帮助您了解每个平台的优势所在,以及如何选择最适合您的方案。
搜索意图以及本指南如何提供帮助
搜索“最佳基础设施监控工具”的用户希望获得一份候选清单、清晰的优缺点分析、价格指南以及对 Kubernetes/云原生技术的支持详情。本指南正是基于此,通过简洁的比较、通俗易懂的解释以及基于 12 年以上服务器、托管和可观测性实践经验的实用建议,为您提供最佳指南。
我们是如何选出这 11 款最佳基础设施监控工具的?
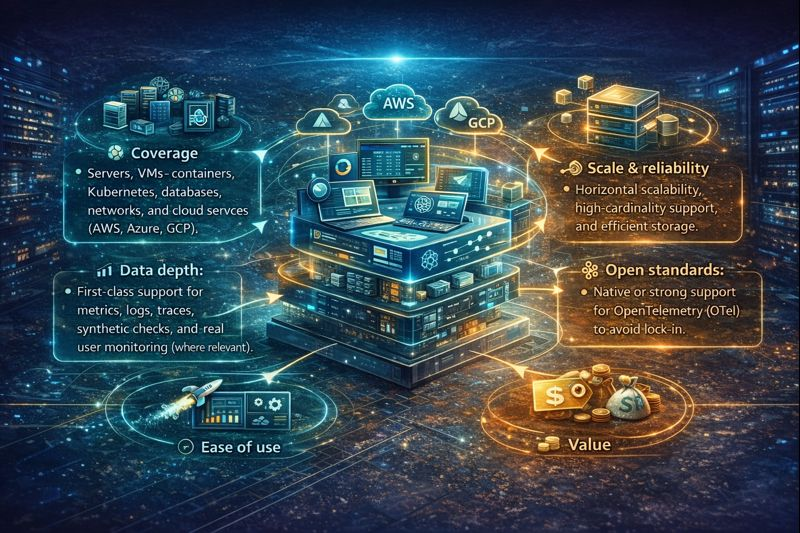
- 覆盖范围: 服务器、虚拟机、容器、Kubernetes、数据库、网络和云服务(AWS、Azure、GCP)。
- 数据深度: 对指标、日志、跟踪、合成检查等提供一流的支持, 真实用户监控 (如适用)。
- 易于使用: 快速上手、自动发现、强大的仪表盘和合理的默认警报。
- 规模和可靠性: 横向扩展性、高基数支持和高效存储。
- 开放标准: 原生或强力支持 OpenTelemetry (OTel),以避免厂商锁定。
- 集成: 适用于常用堆栈的开箱即用插件(Nginx, MySQL(例如 Redis、Kafka、Kubernetes)。
- 价值: 透明的定价、可预测的计费以及2026年预算中总体上强劲的总拥有成本。
2026 年 11 款最佳基础设施监控工具
1.数据狗
Datadog 它将基础设施监控、应用性能管理 (APM)、日志记录、资源使用管理 (RUM) 和安全功能整合到一个 SaaS 平台中,并提供出色的集成和仪表盘。它在云原生和 Kubernetes 环境中表现尤为出色,具备自动发现、拓扑图和机器学习辅助告警等功能。
- 最适合: 需要跨混合架构的统一管理界面的团队。
- 突出特点: 600 多个集成、服务地图、Watchdog(人工智能)、CI 可见性、合成数据。
- 优点(Pros) 快速部署、丰富的生态系统、强大的 Kubernetes 洞察力。
- 缺点(Cons) 规模化后成本可能很高;注意数据量和数据保留情况。
2.动态痕迹
dynaTrace可 它提供深度自动发现、代码级追踪和 Davis AI 根本原因分析功能。对于优先考虑自主运营、精准问题检测和端到端服务健康状况的大型企业而言,它是理想之选。
- 最适合: 企业和受监管行业。
- 突出特点: OneAgent、Davis AI、自动依赖关系映射、Kubernetes 和云智能。
- 优点(Pros) 强大的自动化功能、低噪音警报、性能基准测试。
- 缺点(Cons) 小型团队需要支付更高的价格和更复杂的配置。
3. 新遗物
New Relic的 现在它主要面向OTel,提供广泛的指标、日志和追踪数据采集,以及基础设施监控和APM功能。对于采用开放标准并需要灵活的按需付费模式的团队来说,它非常理想。
- 最适合: OTel 用户,工程团队整合工具。
- 突出特点: 遥测数据平台、APM、Kubernetes Explorer、NRQL 查询。
- 优点(Pros) 强大的数据模型、丰富的集成选项、中等规模下良好的性价比。
- 缺点(Cons) 对于初学者来说,查询和仪表盘可能会感觉很复杂。
4. Grafana 云
格拉法纳云 提供托管的 Grafana 仪表板 managed Mimir(指标)、Loki(日志)和 Tempo(追踪)。对于喜欢开源 Grafana 但又希望获得 SaaS 的便捷性、告警功能和长期存储,而无需自行运行整个技术栈的团队来说,它是理想之选。
- 最适合: 团队从 DIY Grafana + Prom/Loki 迁移到 SaaS。
- 突出特点: 世界一流的仪表盘、警报、综合监控、k6性能测试。
- 优点(Pros) 熟悉开源软件体验,不错的免费套餐,出色的 Kubernetes 可见性。
- 缺点(Cons) 查询学习曲线陡峭;高基数指标需要仔细规划。
5. Prometheus + Alertmanager
普罗米修斯 是抓取云原生工作负载指标的事实标准。与 Alert 配合使用。manage它提供强大而灵活的告警功能。可与 Grafana 配合使用创建仪表盘,并与 Thanos/Cortex/Mimir 配合使用进行长期存储和全局视图查看。
- 最适合: 熟悉开源软件运维的SRE和DevOps团队。
- 突出特点: 基于拉取式抓取、服务发现、PromQL、记录规则。
- 优点(Pros) 免费、Kubernetes原生、高度可扩展。
- 缺点(Cons) 运行高可用性、保留和联合增加了复杂性;日志/跟踪需要额外的组件。
6。 ZABBIX
ZABBIX 是一个成熟的开源平台,具有强大的 SNMP 支持、代理/无代理监控功能,以及适用于服务器、网络设备和应用程序的大量模板库。它对于传统应用来说非常可靠。 数据中心 以及混合配置。
- 最适合: Windows/Linux 混合环境和网络密集型环境。
- 突出特点: 模板、自动发现、升级、灵活的警报。
- 优点(Pros) 无许可费,规模化效率高,社区活跃。
- 缺点(Cons) 用户界面略显过时;Kubernetes原生功能需要额外操作。
7. 弹性可观测性
松紧带 ELK 将日志、指标和 APM 整合在一起,并提供强大的搜索和分析功能。当日志搜索是主要需求时,它非常出色;同时,它还支持基础设施监控和 APM,从而实现全栈可见性。
- 最适合: 日志密集型组织和安全意识强的团队。
- 突出特点: Kibana 仪表盘、机器学习作业、APM 代理、正常运行时间。
- 优点(Pros) 可扩展的搜索、灵活的数据摄取、高性价比的自组织 manage或 SaaS。
- 缺点(Cons) 如果是自托管,则资源消耗较大;调优和生命周期策略需要专业知识。
8.逻辑监控
逻辑监控器 它提供无代理和基于代理的监控功能,并具备强大的服务器、网络设备、存储和云服务自动发现能力。对于希望全面覆盖设备但又不想管理本地环境的 IT 运维人员来说,这无疑是一个绝佳的选择。
- 最适合: 中端市场到企业级混合环境。
- 突出特点: 拓扑映射、动态阈值、广泛的器件库。
- 优点(Pros) 快速见效,强大的网络监控功能,简洁明了的仪表盘。
- 缺点(Cons) 定价面向企业用户;内置追踪功能有限。
9. PRTG网络监视器
PRTG 它采用“传感器”模型来监控网络设备、带宽、服务器和常用应用程序。其引导式设置和可视化地图使其对中小型IT团队极具吸引力。
- 最适合: 中小企业和以网络为中心的监控。
- 突出特点: 自动发现、地图、SNMP/Flow/WMI、可自定义通知。
- 优点(Pros) 轻松上手,许可模式可预测,网络可视性强。
- 缺点(Cons) 日志/追踪信息深度不足;扩展传感器需要规划。
10. 检查
校验码 它兼具高性能和易用性,拥有强大的代理程序、智能服务发现功能和高效的监控核心。在需要可靠性和低开销的混合环境中表现尤为出色。
- 最适合: 寻求以本地部署为先的混合型企业。
- 突出特点: 自动服务发现、直观的规则、强大的Linux/Windows覆盖范围。
- 优点(Pros) 资源高效、实用的用户界面、可预测的扩展性。
- 缺点(Cons) 功能较少,缺乏 SaaS 式的花哨功能;追踪需要外部工具。
11。 ManageEngine OpManager
操作管理器 提供可靠的设备 服务器监控 具有丰富的设备模板和配置功能 manage通过插件提供多种管理选项。对于希望采用 ManageEngine 生态系统进行 IT 运维标准化的团队来说,这是一个经济高效的选择。
- 最适合: IT 团队倾向于使用本地部署工具和统一的 IT 套件。
- 突出特点: 设备模板、NetFlow 插件、配置备份、警报/升级。
- 优点(Pros) 性价比高,设备设置简单,厂商支持广泛。
- 缺点(Cons) 高级可观测性(日志/追踪)需要单独的产品。
快速对比:哪款工具最适合您的工具组合?
- 如果您想要一款能够满足所有需求的 SaaS 产品: Datadog、Dynatrace 或 New Relic。
- 如果你热爱开源和控制权: 普罗米修斯(+警报)manager) 使用 Grafana 或 Checkmk/Zabbix。
- 如果原木是你的重心: 弹性可观测性。
- 如果您的网络规模庞大: LogicMonitor 或 PRTG;OpManager 更适合本地部署,且预算友好。
- 如果您是从 DIY Grafana 迁移过来的: Grafana Cloud for managed OSS 无需繁重工作。
采购指南:2026 年如何选择基础设施监控工具
- 堆栈覆盖率: 确认对您使用的 Kubernetes、容器、服务器操作系统、数据库和云服务提供原生支持。
- 数据深度: 指标、日志、追踪、合成数据和 RUM。如果您只需要基础架构和日志,就无需为高级 APM 支付过高的费用。
- OpenTelemetry: 优先选择OTel数据采集方式,以减少厂商锁定并简化仪器配置。
- 警报质量: 寻找异常检测、SLO/错误预算和降噪措施,以减少寻呼机疲劳。
- 可扩展性: 处理高基数标签(Kubernetes)和长期保留,而不会产生失控的成本。
- 集成: 为您的技术栈选择带有模板和开箱即用仪表板的工具。
- 定价模型: 了解基于数据摄入量和基于主机/传感器的定价方式。估算第 90 百分位使用量,而不是平均值。
- 安全性和合规性: RBAC、SSO/SAML、审计日志、受监管环境下的数据驻留。
实施检查清单(适用于任何工具)
- 库存: 列出所有服务、集群、节点、数据库和网络设备。
- 金色信号: 定义每个服务的延迟、流量、错误、饱和度(以及 SLI/SLO)。
- 基准仪表盘: 创建具有“红/绿”健康状况和向下钻取功能的运行手册。
- 警报策略: 按严重程度进行路由;添加抑制、维护窗口和值班安排。
- 成本控制措施: 标记数据源,按重要性设置保留策略,并限制高基数指标。
# Example: Prometheus alert to catch high error rates on HTTP services
groups:
- name: service.rules
rules:
- alert: HighErrorRate
expr: sum(rate(http_requests_total{status=~"5.."}[5m]))
/ sum(rate(http_requests_total[5m])) > 0.05
for: 10m
labels:
severity: critical
annotations:
summary: "High error rate > 5% for 10m"
description: "Service {{ $labels.job }} is returning 5xx above threshold."真实世界场景与建议
- Kubernetes 密集型创业公司: 先使用 Grafana Cloud 或 Datadog 快速获得价值;如果成本上升,以后再迁移到开源组件。
- 具有严格服务水平协议 (SLA) 的企业: 使用 Dynatrace 或 Datadog 进行 AI 驱动的根本原因分析和自动化依赖关系映射。
- 网络优先的中小企业: 如果以后需要更详细的日志,可以添加 PRTG 或 OpManager;或者添加 Elastic 或 Grafana Cloud。
- 开源偏好: Prometheus + Alertmanager + Grafana,搭配 Thanos/Mimir 进行长期保存;添加 Loki/Tempo 进行日志/追踪。
- 以日志为中心的故障排除: Elastic Observability 加上来自 Prometheus 或原生 Elastic 代理的轻量级指标。
常见问题
监测和可观测性之间有什么区别?
监控收集已知信号(指标、日志、追踪信息)并将其与阈值进行比较。可观测性在此基础上更进一步,通过丰富且相关的遥测数据和上下文信息(服务映射、跨度、属性)使用户能够轻松理解未知问题,从而无需预先定义每个指标即可提出新的问题。
哪款基础设施监控工具最适合 Kubernetes?
Prometheus + Grafana 是 Kubernetes 的原生基线。 manage为了方便起见,Datadog、Dynatrace、New Relic 和 Grafana Cloud 提供自动发现、pod 级可见性和工作负载映射,同时降低了运营开销。
开源工具足以满足企业需求吗?
是的——只要工程投入到位。普罗米修斯警报manager、Grafana、Loki 和 Tempo 可以满足企业需求,尤其是在与 Thanos/Mimir 配合使用时。许多组织选择混合方案:使用开源软件 (OSS) 来获取基线指标/日志,并使用软件即服务 (SaaS) 平台进行高级分析和事件响应。
基础设施监控工具的价格是多少?
费用因定价模式而异: 基于主机或传感器(PRTG、OpManager)、使用/摄取(Datadog、New Relic、Grafana Cloud、Elastic)或完全自组织 managed(Prometheus/Zabbix/Checkmk)。估算峰值摄取量、基数和保留量,以避免账单超支,并标记遥测数据以执行数据策略。
为了快速减少停机时间,我们应该首先监控哪些方面?
首先关注影响最大的服务,重点关注延迟、流量、错误和饱和度等关键指标。然后对数据库、队列和外部依赖项进行健康检查。制定清晰的值班表、可操作的警报和运行手册。最后,扩展到日志/跟踪和 SLO,以确保服务的持续可靠性。
结语
到 2026 年,“最佳”基础设施监控工具应该是能够完美契合您的技术栈、技能水平和预算,并且能够轻松扩展的工具。使用这份候选清单,将需求与功能相匹配,从高影响力信号入手,并逐步稳步发展。如果您需要专家协助部署规模合适的技术栈, YouStable 可以全程指导您。

